С ростом числа команд взаимозависимости между ними множатся и все больше времени уходит на согласование шагов. Десятки команд начинают мешать друг другу. Чем больше организационная структура заточена под узкую специализацию команд, тем больше требуется внешней координации. И вместо того чтобы тратить время на создание ценности, люди тратят его на бесконечные совещания и уточнения, кто за что отвечает.
Когда нет общего фокуса, разные команды могут работать вразнобой — каждая движется в свою сторону, теряя из виду общую цель. Начинается гонка локальных улучшений — все стараются сделать лучше свой кусочек, но целостной картины при этом не получается. Становится трудно понять, что на самом деле важно для клиента. В итоге команды могут застрять в технических деталях и нескончаемых согласованиях, теряя из виду главное — реальную ценность продукта. В больших компаниях это часто приводит к тому, что продукт превращается в набор параллельных проектов, а не цельное решение для пользователя.
Когда компании начинают масштабироваться, часто в ответ появляется больше правил, ролей и формальных процедур. Казалось бы, это должно навести порядок, но на деле – еще больше замедляет работу. Новые уровни менеджмента создают узкие места — решения принимаются медленно, издержки растут, а у команд падает мотивация. Все эти проблемы взаимосвязаны и подпитывают друг друга.
- Хаос координации порождает бюрократические костыли для его преодоления.
- Бюрократия еще сильнее отдаляет команды от продукта и клиента.
- Потеря продуктового фокуса усиливает разноголосицу приоритетов, что в свою очередь вносит еще больший хаос.
Фреймворки масштабирования Agile были созданы именно для того, чтобы структурировать взаимодействие множества команд и сохранить гибкость и продуктивность работы. Large-Scale Scrum (LeSS) – один из таких подходов, он упрощает структуру организации, стремясь убрать сами причины перечисленных проблем.
LeSS Huge – это специальная конфигурация LeSS для действительно крупных продуктовых групп. Он нацелен на то, чтобы адресовать перечисленные боли системно – не просто через локальные “костыли”, а через изменение организационной структуры и принципов работы.
Мы можем помочь избежать многих сложностей, внедрив Agile на уровне всей компании или отдельных команд, и обучив руководителей среднего и высшего звена эффективно проводить изменения.
Структура LeSS Huge
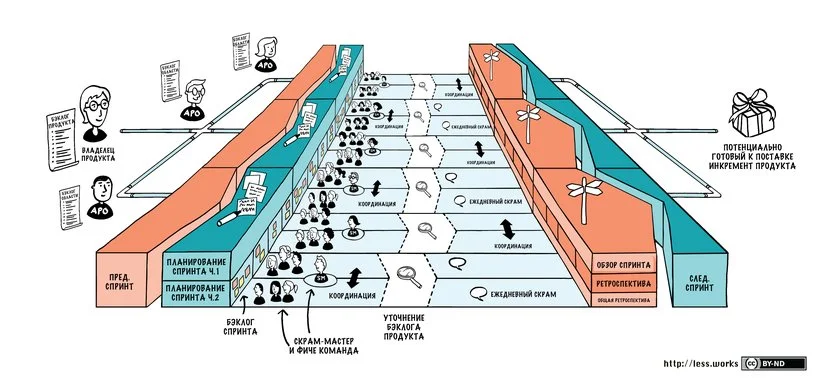
LeSS Huge создан специально для случаев, когда над одним продуктом работает более 8 команд, то есть свыше 50 человек. Это расширение базового LeSS с минимально необходимыми дополнениями для большой масштабности. Даже при десятках команд продукт остается единым, с единой “командой” из множества команд, совместно выдающих один интегрированный инкремент за спринт.
Как сохранить фокус на клиентских ценностях
В LeSS Huge весь продукт разбивается на крупные Области Требований (Requirement Areas). Это не технический модуль и не отдел организации, а логическая часть продукта, выделенная по признаку ценности для клиента. Иначе говоря, каждая область – это определенная группа функциональностей продукта, которые объединены общей идеей, близкой с точки зрения пользователя. Например, в случае сложной финансовой системы отдельными областями могут быть «Обработка транзакций», «Сервис активов клиентов», «Подключение новых рынков»и т.д. – каждое из этих направлений представляет отдельную ценность для пользователя или бизнеса.
Область Требований – не компонент и не подсистема в инженерном смысле. Это скорее направление потребностей клиента. Элементы бэклога в такой области формулируются как функции или истории, несущие законченную ценность. Например, в области “Поиск и навигация” для e-commerce продуктa элементом бэклога может быть “Реализация фильтрации товаров по характеристикам” – задача, которая затрагивает и фронтенд, и бекенд, и базу данных, но целиком относится к улучшению клиентского опыта поиска. Динамичность областей – еще одно их свойство. По мере развития продукта области требований могут дробиться, укрупняться или меняться, чтобы лучше соответствовать актуальным бизнес-потребностям.
Для каждой Области Требований ведется Area Backlog – представление общего Product Backlog, отфильтрованное по данной области. Проще говоря, общий Бэклог продукта помечается атрибутом области, и по каждой области мы можем видеть ее собственный срез бэклога. Приоритезация требований внутри области – ответственность специального Владельца продукта по области, но при этом все эти кусочки все равно принадлежат одному общему бэклогу продукта.
Кто такой Area Product Owner
В классическом LeSS с 2–8 командами по-прежнему есть один Владелец Продукта. Он устанавливает приоритеты в едином бэклоге и работает напрямую со всеми командами. Однако когда масштаб переваливает за определенный порог (больше 8 команд), один человек физически уже не успевает держать в голове весь контекст продукта, общаться со всеми стейкхолдерами и отвечать на вопросы десятков разработчиков. Именно в этот момент и нужен переход к LeSS Huge. Но важно, что в LeSS Huge у каждого компонента свой продукт и свой PO.
В LeSS Huge вводится команда помощников для единого Product Owner’a – Area Product Owners (APO) или Владельцы продукта по областям. Как следует из названия, каждый APO фокусируется на одной Области Требований и управляет соответствующим Area Backlog. Для команд, работающих в этой области, APO выступает практически как привычный Product Owner: уточняет требования, определяет локальные приоритеты, детализирует истории, участвует в планировании спринта и обзорах в контексте данной области.
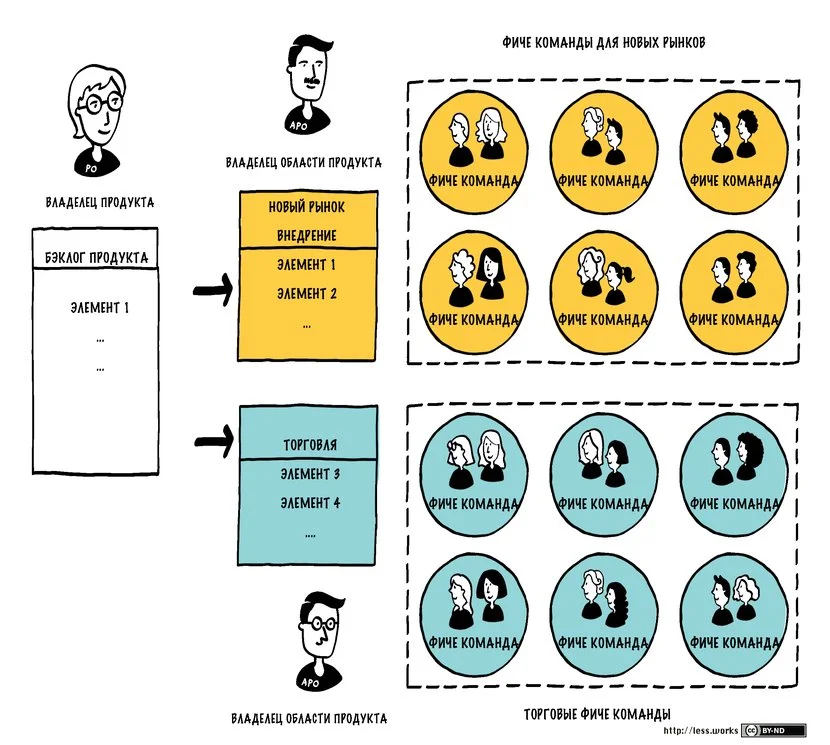
При этом в LeSS Huge остается один общий Владелец Продукта (Chief PO) на весь продукт. Его зона ответственности – целостная оптимизация продукта, стратегическое направление и связка всех областей между собой. Он же развивает своих Area PO, делегируя им детальную работу. Таким образом, роль PO становится многоуровневой, но не дробящей продукт. Владелец продукта по области фактически делает то же, что и Владелец всего продукта, только в более узкой части. В то же время все APO синхронизируются между собой через общего PO, который следит, чтобы приоритеты во всех областях соответствовали общей продуктовой стратегии. Важно, что APO не конкурируют за ресурсы и внимание, а совместно соотносят свои области с общим направлением развития.
О том, как Владельцу продукта управлять ожиданиями заказчиков, работать внутри Agile-команды и развивать продукт, опираясь на реальные потребности клиентов — мы подробно разбираем на тренинге для всех, кто хочет освоить современные методики создания востребованных продуктов. Можем провести его в корпоративном формате отдельно для выбранных команд.
Как в LeSS Huge организованы командное взаимодействие и координация
В LeSS Huge, как и в базовом LeSS, все команды работают над единым инкрементом продукта в общем спринте. Нет разбивки на проекты со своими циклами – спринты синхронизированы по всем Областям Требований. Это решение заставляет организациюинтегрировать результат постоянно, от спринта к спринту, а не складывать части в конце квартала или года. Даже если у вас 15–20 команд, LeSS Huge предполагает одну дату начала и окончания спринта для всех, один Sprint Review, где демонстрируется потенциально выпускаемый продукт, включающий работу всех команд.
Конечно, синхронно работать стольким командам – задача нетривиальная. Ключевую роль играет техническая культура – практики Continuous Integration (CI) и автоматизация позволяют командам ежедневно интегрировать код друг друга и быстро выявлять проблемы. LeSS Huge активно поощряет непрерывную интеграцию на уровне всего продукта. В идеале, добавление новых функций в любой области ежедневно проверяется на совместимость со всем остальным.
Требования стараются разрезать по областям так, чтобы зависимостей между областями было как можно меньше. Внутри каждой области работает от 3 до 8 кросс-функциональных команд, организованных по принципу фиче-команд. Каждая такая команда способна реализовать задачу «под ключ» внутри своей области. Вместо того чтобы строить работу на передаче задачи от аналитиков к разработчикам, потом к тестировщикам и далее, в LeSS формируются стойкие мультидисциплинарные команды, которые сами выполняют все этапы. Узкие специализированные отделы расформировываются, вместо них – автономные команды, способные разобраться и в UI, и в базе данных, и в бизнес-логике.
Проще говоря, командам в меньшей степени приходится ждать друг друга – большинство вопросов они закрывают сами.

В LeSS Huge активно используются совместные мероприятия по продуктовому бэклогу. Общие встречи по уточнению бэклога (PBR, Product Backlog Refinement) проводятся регулярно с участием нескольких команд одновременно. На таких сессиях команды вместе с главным Product Owner’ами или Area PO разбивают крупные элементы на понятные истории, обсуждают открытые вопросы, оценивают сложности и риски. Важно, что PBR в LeSS Huge может проводиться как в масштабах отдельных Областей Требования, так и с участием всех ключевых людей по продукту, когда обсуждаются крупные элементы, затрагивающие несколько областей сразу.
После общей очистки бэклога команды в LeSS Huge проводят привычное Планирование спринта (Sprint Planning). Обычно оно делится на две части. Первая часть – все Area Product Owner’ы и представители команд встречаются вместе, чтобы ориентировочно решить, какие команды какие элементы из общего бэклога берут в работу в новом спринте. Здесь важно убедиться, что суммарно команды покрыли самые приоритетные задачи продукта. Вторая часть – каждая команда детально планирует свою работу уже отдельно в рамках выбранных историй вместе со своим APO.
Ежедневная координация осуществляется большей частью самоорганизованно. Раз уж все в одном спринте и работают над одним инкрементом, команды держат связь напрямую друг с другом по мере необходимости. Если две команды обнаружили между собой зависимость, в LeSS ожидается, что они сами ее решат – созвонятся, соберутся в комнату и привлекут нужных специалистов. В случае больших групп практикуются неформальные короткие синхронизации представителей от команд, чтобы поделиться статусом и проблемами между командами. Но решения все равно принимаются самими командами, просто появляется дополнительная точка обмена информацией.
По окончании спринта все команды участвуют в общем обзоре спринта, где стейкхолдерам показывается интегрированный инкремент продукта. Масштаб не служит оправданием, чтобы предъявить частично готовые разрозненные куски – показывается именно цельный продукт, пусть и с неполным набором функций.
А после обзора проводится ретроспектива. Помимо командных ретроспектив LeSS Huge предусматривает общую ретроспективу на уровне всего продукта. Обычно в ней участвуют представители всех команд, Product Owner и Scrum-мастера. Эта встреча посвящена тому, как группы сработались между собой, где были проблемы с координацией и какие системные препятствия мешают командам.
Чем LeSS Huge отличается от обычного LeSS
LeSS Huge вводит только то, что строго необходимо, чтобы масштабировать Scrum-принципы дальше. Правило базового LeSS:
Один продукт = один бэклог = один Product Owner, даже если команд несколько.
Это работало в кейсах до 8 команд. Но когда команд становится, скажем, 15 или 20, один человек уже не в состоянии эффективно общаться с сотней разработчиков, десятками заказчиков и управлять сотнями элементов бэклога каждый спринт. Организации, игнорирующие этот предел, сталкиваются с двумя сценариями. Либо PO становится узким горлышком, не успевая отвечать командам и обновлять приоритеты, либо фактически другие люди начинают принимать продуктовые решения вместо него, размывая ответственность. LeSS Huge формально отмечает этот порог.
От 8 команд вводим Requirement Areas и Area Product Owners.
Это структурное решение – разгрузить мозг одного человека, разделив продуктовую экспертизу по областям, но не дробя сам продукт. LeSS Huge сохраняет единый продукт – один общий PO руководит общей картиной, а APO – его расширенные руки и глаза в каждой части продукта. Глубинная причина, почему так важно сохранить одного Product Owner’а – необходимость целостной оптимизации продукта.
Как области требований в LeSS Huge заменяют структурные отделы
В традиционной большой организации команды часто группируются по компонентам (например, фронтенд-команда, команда мобильного приложения или команда бэкэнда) или по функциональным отделам (отдел разработки, отдел тестирования или отдел аналитики). При таком делении поток работы проходит через множество узких мест, и менеджмент вынужден координировать взаимодействие этих групп.
Область требований – это практически автономный мини-продукт внутри большого, который приносит конкретную ценность пользователю. Команды внутри области обладают всеми навыками, чтобы эту ценность поставлять напрямую. В результате координация требуется внутри областей. Например, если выделена область “Управление аккаунтом клиента” – то 5-6 команд этой области сами решают 90% задач по реализации любой фичи, связанной с аккаунтом. Им редко нужна помощь команд из другой области. В тех случаях, когда межобластная работа все же нужна, она обычно касается более высокоуровневых элементов и тогда в игру вовлекаются соответствующие APO и главный PO, чтобы объединить усилия.
Области требования – это не синоним компонента. Если бы мы разделили продукт по техническим компонентам, мы бы вернулись к ситуации, где ни одна команда не может создать ценность самостоятельно. Это та самая ловушка, в которую попадала Nokia и множество других компаний.
Узкие специализированные компоненты -> требуются тонны внешней координации -> медленно, дорого, непрозрачно.
Как с минимумом новых ролей сохранить простоту структуры
В больших масштабах легко впасть в соблазн создать сложную иерархию – главных менеджеров, программных менеджеров, координаторов и так далее.
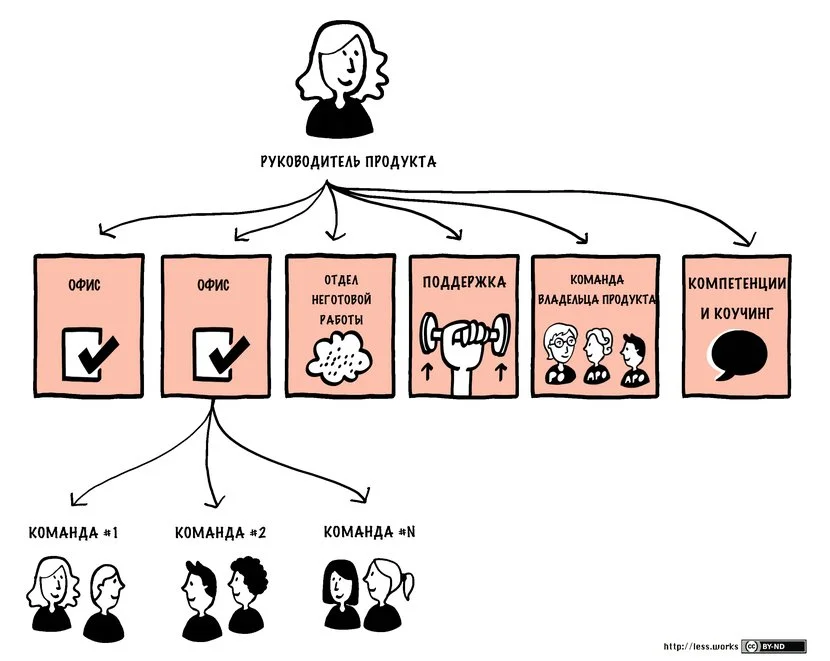
Кроме введения роли APO, никаких новых ролей не добавляется. Нет должности Руководитель программы или Solution Architect, нет отдельной вертикали руководителей релизов, как RTE в SAFe, или потоковых менеджеров – ничего такого.
Организация по LeSS Huge становится плоской. Одна продуктовая группа, один Product Owner и несколько его Area PO, и несколько Scrum-мастеров, помогающих всем им совершенствовать процесс. За счет этого радикально снижается организационная сложность. Меньше людей не занятых созданием ценности, меньше отчетностей и статусов, меньше искусственных границ между командами. LeSS буквально расформировывает лишние контрольные функции, чтобы заставить команды выстраивать прямое взаимодействие. Поначалу это сложно, ведь легче спросить начальника, что делать, чем самим договориться с соседней командой, но в итоге формирует гораздо более зрелую и гибкую организацию.
Дополнительные слои и роли, помимо издержек, вводят иллюзию, что проблемы решаются. Например, найм новых менеджеров проектов для координации. Но координаторы проблемы не устраняют, они лишь превращают явные сбои в форму регламентов и совещаний, где время все равно тратится, только скрыто. LeSS Huge, следуя принципам Lean, выбирает устранение корневых причин вместо управления последствиями. Вместо того чтобы назначить ответственного за межкомандные зависимости, LeSS предлагает убрать сами зависимости через реорганизацию команд и увеличение контекста областей. В итоге коммуникации становятся короче и быстрее.
Вместо Product Manager → Program Manager → Team
Один уровень Product Owner → Teams
Как внедрить LeSS Huge
Если базовый LeSS рекомендуется внедрять разом, то для LeSS Huge прямолинейный big-bangподход не сработает. Слишком много одновременно нужно изменить в очень большой системе. Поэтому авторы LeSS рекомендуют пошаговое развертывание LeSS Huge. Обычно предлагают два пути на выбор или комбинацию.
Запускать LeSS сначала в пределах одной области требований, отточить подход на ней, а затем добавлять следующую область, и так далее. Например, выбрали наиболее независимую область продукта, перевели там команды на LeSS, получили успехи – и используем этот опыт, чтобы подключать следующие области. Шаг за шагом вся организация трансформируется, но не сразу целиком, а область за областью.
Либо постепенно расширять границы продукта и ответственности команд. Начать можно даже с одной области или части продукта, а затем увеличивать сферу, в которой команды работают по LeSS-принципам: например, сначала включить одну смежную компоненту в периметр фиче-команд, потом еще одну, и т.д., пока все нужные компоненты и функции не войдут. Параллельно расширяется Definition of Done продукта.
Оба подхода означают, что крупная организация какое-то время будет жить в гибридном состоянии – частично по LeSS, частично по старым структурам. Это нормально и даже неизбежно – большие изменения лучше усваиваются постепенно. Начните с небольшого эксперимента, посмотрите, приносит ли он лучшие результаты, и если да — постепенно масштабируйте успех. Такой подход снижает сопротивление изменениям – люди видят живой пример, команды успевают адаптироваться к новой культуре, топ-менеджмент получает доказательства эффективности прежде, чем решиться ломать всю структуру.
LeSS Huge – это все тот же Scrum, примененный к очень большому продукту и сохранивший его дух.
Реальные примеры неудачного масштабирования
Специализированные компоненты
Ситуация. Компания быстро росла и команды формировали по техническим компонентам – отдельно фронтенд, серверная часть, команда DBA, тестирование и так далее. Но по мере роста продукта выяснилось, что каждая пользовательская функция требует участия всех этих команд. Чтобы выпустить даже небольшое обновление, нужно было синхронизировать 5–7 разных групп. Возникли сложные графики релизов, очереди задач между отделами, постоянные созвоны менеджеров проектов. Темпы разработки упали – большое изменение требовало месяцы согласований.
В ответ менеджмент усилил контроль, ввел еженедельные статус-митинги со всеми лидерами, назначил специальных координаторов, которые отслеживали взаимозависимости. Это лишь увеличило бюрократическую нагрузку – инженеры тратили половину недели на совещания и отчеты. Несмотря на все старания, интеграционные проблемы обнаруживались в конце цикла – компоненты были несовместимы друг с другом, и приходилось тратить дополнительное время на правки.
Как помог LeSS Huge. Вместо компонентных команд появились кросс-функциональные фиче-команды, способные сами выполнять всю работу от UX до базы данных. Вместо разрозненных отделов – продуктовые области, внутри которых зависимость команд друг от друга минимальна. Если бы в вышеописанной компании применили LeSS Huge, то, скажем, 6 команд работали бы вместе над целостным куском функциональности (областью требований) и имели нужную экспертизу внутри команды, чтобы реализовать любую историю без передачи задачи на сторону. Это устранило бы большую частьочередей – просто некого было бы ждать, команды все делают сами.
Там, где зависимости между областями все же остаются, LeSS Huge предлагает выявлять их заранее на общих PBR и решать через прямое общение команд, а не через многоуровневое администрирование. И самое главное – здесь бы не потребовались множества координаторов и менеджеров. Лишние роли сами отмерли бы за ненадобностью, когда люди начали бы напрямую договариваться. Конечно, перейти сразу от компонентных к фиче-командам непросто – поэтому LeSS Huge рекомендует постепенный переход, например, сначала объединить разработчиков и тестировщиков в одной команде, потом подтянуть аналитиков, и так далее.
Чтобы сотрудники быстрее освоили работу в кросс-функциональных командах и научились гибко адаптироваться к изменениям, мы проводим корпоративные тренинги с учетом индивидуальных запросов конкретной команды.
Каждая команда сама по себе
Ситуация. Организация, пытаясь быть Agile, дала автономию каждой из множества команд. У каждой команды – свой Product Owner или менеджер, который общается со своими стейкхолдерами и решает, что делать. Сначала команды работали параллельно и каждая выпускала что-то свое. Но вскоре обнаружилось, что продукт перестал быть цельным, разные части системы развивались вразнобой. Например, веб-версия продвинулась в функционале, а мобильное приложение отстало и не поддерживало новые возможности. Одни модули реализовали одну бизнес-логику, а другие – противоречащую ей. Пользователи жаловались на непоследовательность опыта.
Внутри компании возникли конфликты приоритизаций: отдел А требовал от команды X немедленно сделать функцию P, потому что у них OKR, а отдел B давил на эту же команду X с другим запросом. Без единого Владельца продукта эти споры решались – чей начальник убедительнее. Время и энергия тратились на конкуренцию ресурсов, вместо сотрудничества. В итоге некоторые сильные специалисты покинули команды, разочаровавшись, а оставшимся все труднее было понимать, куда движется компания.
Руководство, увидев проблему, пыталось ввести “стратегический комитет”, который раз в полгода сверстал бы общий roadmap. Но к тому времени каждый «мини-PO» уже тянул одеяло на себя, и договориться о едином плане было почти нереально. В результате компания за несколько лет так и не выпустила ни одной действительно интегрированной версии продукта – клиент получал либо сырые прототипы, либо обещания.
Как помог LeSS Huge. В основе LeSS Huge заложен единый продукт с единым бэклогом и единым направлением. Каким бы большим ни был продукт, у него остается один Product Owner, отвечающий за целое. В описанном случае LeSS Huge вообще бы не позволил формально появиться множеству несвязанных PO – вместо этого была бы выстроена команда APO вокруг единого PO. Все Area Product Owner’ы регулярно работают с главным PO, синхронизируя приоритеты. Практически это может выглядеть как еженедельные встречи всех APO с Chief Product Owner, где обсуждается прогресс и планы каждой области.
Кроме того, LeSS Huge предполагает общий Sprint Review – то есть каждые 2-4 недели вся верхушка видит интегрированный результат. Если какой-то модуль отстает – это станет очевидно на демо, и общий PO сможет перераспределить внимание. Даже если единый бэклог разделен на части по областям, у главного PO всегда есть полная картина и возможность перетасовать приоритеты между областями. Например, если мобильное приложение начало отставать, главный Владелец продукта может поднять задачи мобильной области выше в общем приоритете или даже перебросить пару команд из другой области временно на усиление мобильной.
Как масштабироваться, уменьшая сложность
LeSS Huge – это взгляд на масштабирование продуктовой разработки через призму упрощения. Опыт больших компаний показывает, что усложнение ради контроля ведет к тому, что организации становятся неповоротливыми, теряют новаторство, а сотрудники – мотивацию. LeSS Huge позволяет структурно заложить единый фокус на продукт, синхронизировать все команды на ценности для клиента и убрать барьеры между людьми. Да, это требует смелости и доверия: доверия к командам, что они справятся без менеджеров над ними, и смелости упростить структуру, возможно, сократив чьи-то привычные должности или перераспределив ответственность. Но выигрыш – колоссальный. Вместо хаоса – упорядоченный ритм единой многокомандной Scrum-группы. Вместо бюрократии – прямое взаимодействие и прозрачность.
LeSS Huge не обещает, что станет легко – большие продукты по определению сложны. Однако он показывает, как управлять этой сложностью с помощью первоначальных agile-принципов – через людей и их взаимодействие, через работающий продукт, через сотрудничество с заказчиком, через готовность меняться. Упрощая организацию, мы высвобождаем потенциал команд и их ориентированность на результат.
В итоге выигрывают все. Бизнес получает более быстрые и качественные поставки, команды – ощущение общей победы и причастности к большому делу, клиенты – цельный продукт, который постоянно улучшается. Чтобы успешно масштабироваться на большие продукты, нужно парадоксально уменьшить сложность, восстановив прямую связь между усилиями множества людей и ценностью для пользователя.
Обсудить масштабирование Scrum и внедрение LeSS для вашей организации, учитывая особенности существующей культуры, можно на корпоративном тренинге LeSS Professional. Мы проведем его специально для вашей команды и поможем разобраться, как выстроить эффективную структуру внутри вашей компании с помощью LeSS.
Мы подготовили серию статей о Large-Scale Scrum и постарались простым языком объяснить, как работает LeSS и как применять его на практике. Статьи можно читать в любом порядке.
Введение в LeSS (Large-Scale Scrum) Роли и организационная структура в LeSS Процесс спринта и события в LeSS Как техническое совершенство в LeSS помогает сохранить качество и гибкость при масштабировании Принципы и ценности LeSS Внедрение LeSS в организации